这学期在学校选修了一门名为「大数据分析技术导论」的公选课,课上纲领性的介绍了目前正处风口的大数据时代的特点,数据挖掘技术的操作过程和实际应用,并从统计分析基础和数据分析工具介绍两方面介绍了一些实践性质的内容。因为是导论性质的课程,课堂内容侧重介绍和应用的性质居多,而对围绕 Hadoop 和 Spark 的实际大数据技术栈,只简单按分类介绍了 MapReduce 、 NoSQL 类数据库、数据集成等常用工具的功能和使用场景,除了最后一节课以 Weka 为例示范了简单的数据集统计分析和经典机器学习模型训练,其他并没有深入讲解到实践操作部分。
作为课程考核的一部分,在分析论文、利用数据集进行分析实验两个选题中,我选择了后者。因为不可能有合适的平台练习分布式存储、批处理和持续集成,最后决定自己爬取一份数据,把简单数据可视化分析的流程跑通。中间踩坑的过程非常多,实际上大部分的想法都没有成功,但是尝试的过程中,对大数据领域工作流和技术栈的加深了解,应该算是达到了这个导论课本身的意义。
BigDataGumi 动画评分数据可视化分析
这篇文章记录了利用 Bangumi 番组计划 (bgm.tv) 网站的动画条目和评分数据,进行数据统计分析的项目「BigDataGumi」的初步进展,包括设计网页爬虫抓取数据、利用可视化分析工具尝试获取有价值信息的实际操作部分。一些没有实现的想法和没有呈现在结果中的可能的学习方向,也会作为学习经历的一部分记录。项目的下一步想法是训练一个 tag-orinted 的机器学习模型,能够计算动画的 STAFF 构成和 TAG 标签属性对评分影响的权重,并根据 STAFF 和 TAG 数据预测新番的最终稳定评分,在撰写本文时仍在进行中。
尽管这个项目目前的进展不怎么大数据,不过如果你和之前的我一样从未接触过数据挖掘这个领域,从这篇文章你可以看到简单的数据爬取和可视化分析的操作流程,并且了解到数据分析部分领域的概貌。涉及到的都是非常粗浅的内容,见笑。
环境准备
环境准备
在可视化分析阶段,我们主要使用在线工具,因此需要提前配置好开发环境的就是之前的数据爬取阶段。

环境准备 详情
在获取数据方面,有一个知名的在线付费服务 import.io 。如果自己动手,网页爬虫脚本的业界事实标准是 Python 的 scrapy 库,配合 python-rq 还可以实现分布式运行。当然你还可以用 BeautifulSoup 配合 request 和 urllib2 库从更底层的地方开始手写。不过,从入手效率方面考虑,这里我选择的是 binux 学长的 pyspider 。尽管功能相对简单不适合用于生产环境,但是其设计亲民的在线 IDE 几乎能让任何一个有 HTML 基础的人在几分钟内上手,拿到想要的数据。
写出简单的脚本,只需要初步的 Python 和 HTML 基础。然而,大部分有价值的信息,其数据源网站都会做反爬虫处理,后来尝试抓取拉勾网数据时我就踩到了不少这类坑。简单的反爬虫措施, 一般可以用修改 UA ,利用 node.js 平台的 PhantomJS 以及替代者 Headless Chrome 模拟浏览器,控制访问来源地址、并发数量和频率等思路解决。如果深入学习,也是个大坑。
Anaconda 和 PySpider
正如其标语「The Most Popular Python Data Science Platform」, Anaconda 不仅能一键安装,比较便利的搞定一个 Python 环境,同时自带了或者能很便利的安装数据分析的许多常用工具集。接下来用到的 numpy 、 pandas 和 jupyter notebook 环境都随 Anaconda 预先安装了。
要注意的一个坑是,截止撰文时 PySpider 仍未完成 Python 3 的支持,需要 Python 2 环境运行。因此如果需要管理多个 Python 版本,可以考虑使用 pyenv 或者 virtualenv ,个人经验后者似乎更方便。
数据爬取
数据爬取

目标数据设计
在动手编写网页爬虫脚本前,一定要预先设计好你想获得的数据,以及大概计划进行哪些类型的分析,而不是觉得数据多多益善,先抓再说,这是惨痛的教训。
在设计目标数据时,要注意的时尽可能的多获取格式规范的数据、尤其是量化的数值型数据,因为这一类数据可以经过较少的处理步骤而直接输出。而格式复杂的日期数据,以及文本和标签数据,都需要经过后期的结构化提取,才能让大部分的工具支持分析。
根据 Bangumi 番组计划的动画条目特征,最后决定将动画原文标题和译名、左侧的制作信息和 STAFF 表、用户为动画打的标签和标记人数、观看进度想看看过等标记人数、打分 Score 排名 Rank 和 1 ~ 10 每个分数段的打分人数都抓取下来。
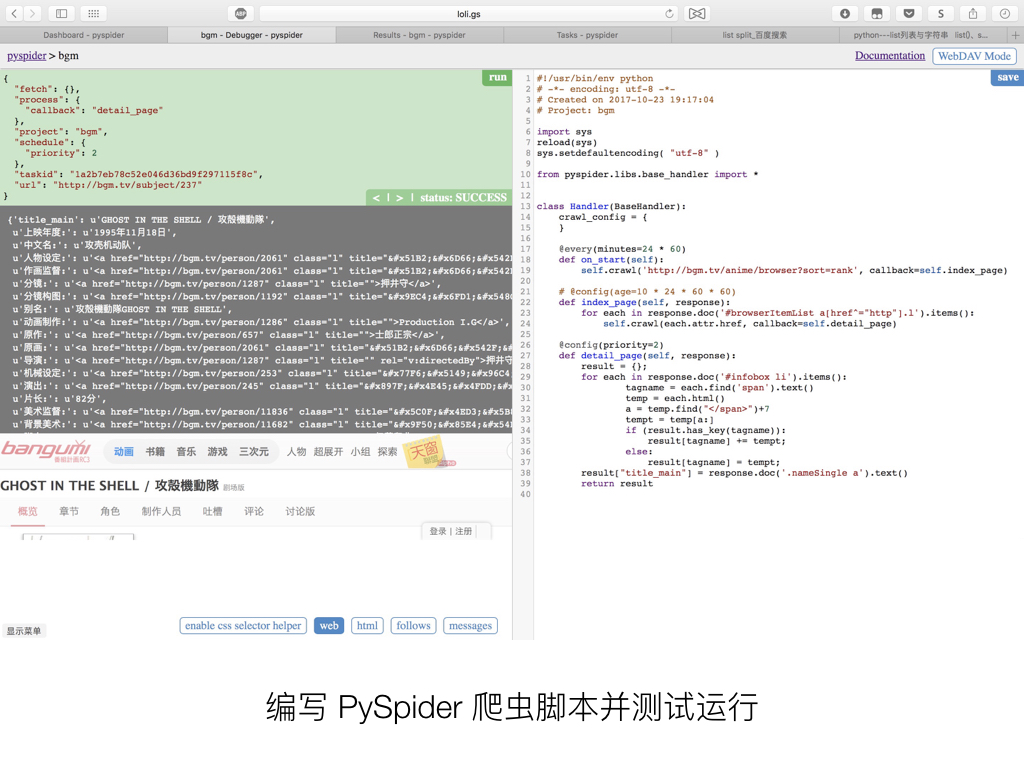
编写 PySpider 爬虫脚本并测试运行
在测试机上运行 PySpider 服务器,进入后台并新建一个爬虫任务,编写脚本。
建议通读 PySpider 的官方英文文档 (不建议参考年久失修的中文官网),并不复杂,参照示例代码编写就可以很快上手。其中在对网页的 HTML DOM 结构进行操作的时候, PySpider 使用的是 PyQuery ,一个类 jQuery 的 DOM 查询库,因此如果需要编写复杂的页面查询,还需要阅读 PyQuery 的官方文档 。
PySpider 的可视化 IDE 设计非常易用,在右边编写 Python 脚本时,你可以在左边实时浏览目标页面,并且查看抓取到的地址列表或者 JSON 数据(或者说是 Python 对象),并且手动操作单步抓取。
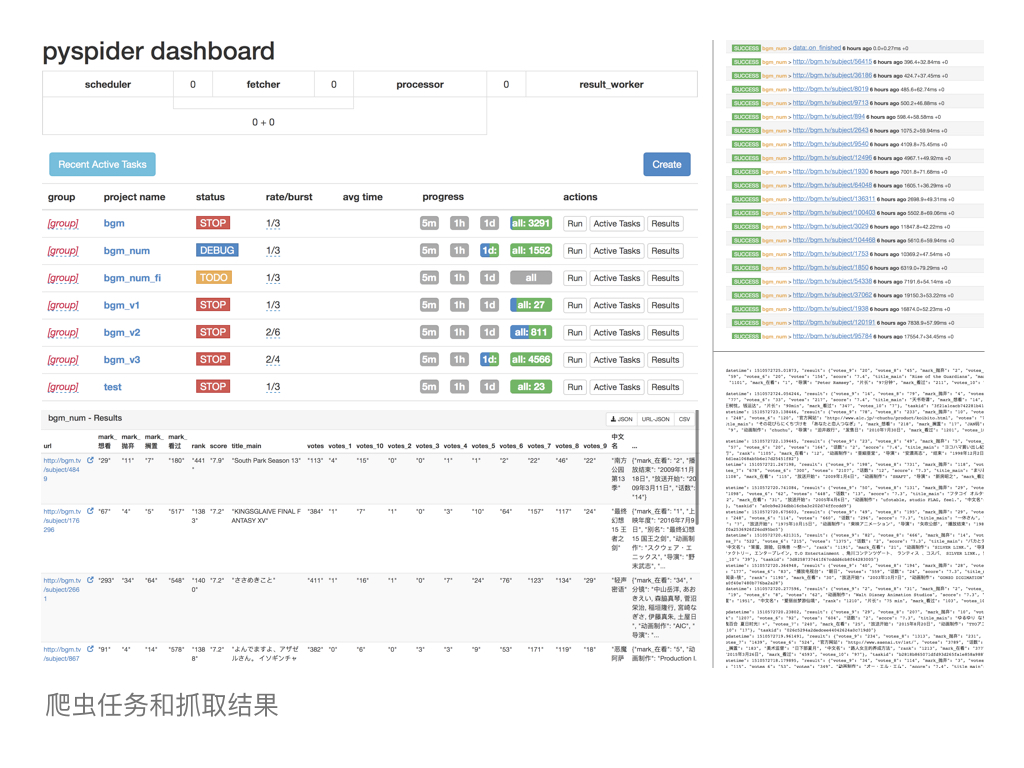
爬虫任务和抓取结果
设置好并发数量,设置任务属性为 DEBUG 或者 RUN 并开始任务,爬取操作就会开始。在 dashboard 页会显示任务进度和抓取成功率, Active Tasks 页面会显示最近页面抓取操作的 LOG 和是否成功,在 Result 页面就可以直接以表格形式在线预览抓取结果,或者导出 JSON 或 CSV 了。
抓取到的一条 JSON 数据大概是这样的(不含 TAGS 标签):
{"url": "http://bgm.tv/subject/265", "updatetime": 1510571847.302935, "result": {"votes_9": "2692", "votes_8": "1362", "mark_抛弃": "66", "votes_1": "40", "votes_3": "16", "votes_2": "9", "votes_5": "68", "votes_4": "26", "votes_7": "562", "votes_6": "224", "votes": "8677", "话数": "26", "score": "9.0", "title_main": "新世紀エヴァンゲリオン", "mark_想看": "896", "mark_搁置": "298", "中文名": "新世纪福音战士", "rank": "4", "mark_在看": "339", "放送开始": "1995年10月4日", "动画制作": "GAINAX, タツノコプロ", "导演": "庵野秀明", "播放结束": "1996年3月27日", "mark_看过": "10801", "votes_10": "3678"}, "taskid": "22e5e52633f60552e28b4e49b29f5073"}
CSV 是数据集最常用的格式,也是个设计十分简单的格式。然而当结果对象属性太多,或者说数据栏目过多时,在 PySpider 直接导出 CSV ,会有一部分被折叠成 JSON 。尝试了一些现有的 json 到 csv 的转换工具都不好用,因此我决定导出 JSON 之后,手动编写一个 Python 脚本对 JSON 进行处理,按自己需要的方式展开,并正好对格式有误的数据进行整理。
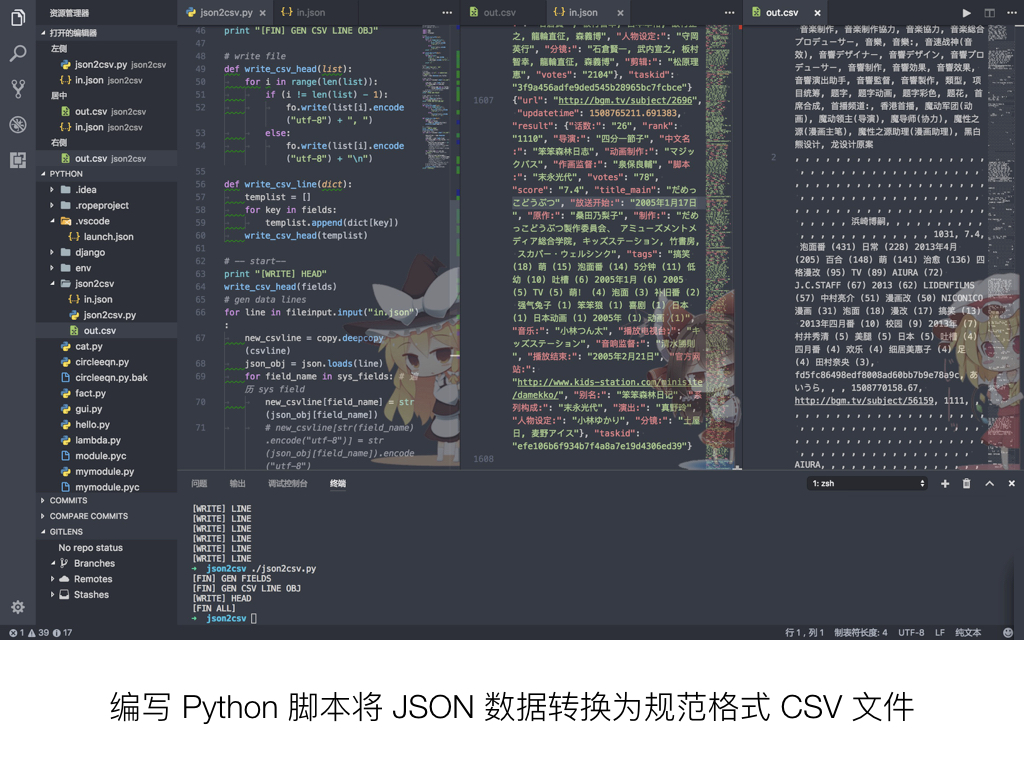
编写 Python 脚本将 JSON 数据转换为规范格式 CSV 文件
因为 Python 对象和 JSON 的结构十分类似,利用原生 json 库进行转换也很好用,需要导出的 CSV 格式也只是按逗号 , 分割条目的纯文本,因此脚本本身并不复杂。当然,要注意把数据内容中的逗号 , 替换掉,以免冲突。
这里面遇到的最大的坑其实是 Python 的 Unicode 文本处理,因为数据内容中由大量 UTF-8 的中文文本,也就是 u’文本’ 形式的对象,必须在适当的时候进行 utf-8 的 encode 和 decode 操作,否则会导致乱码。
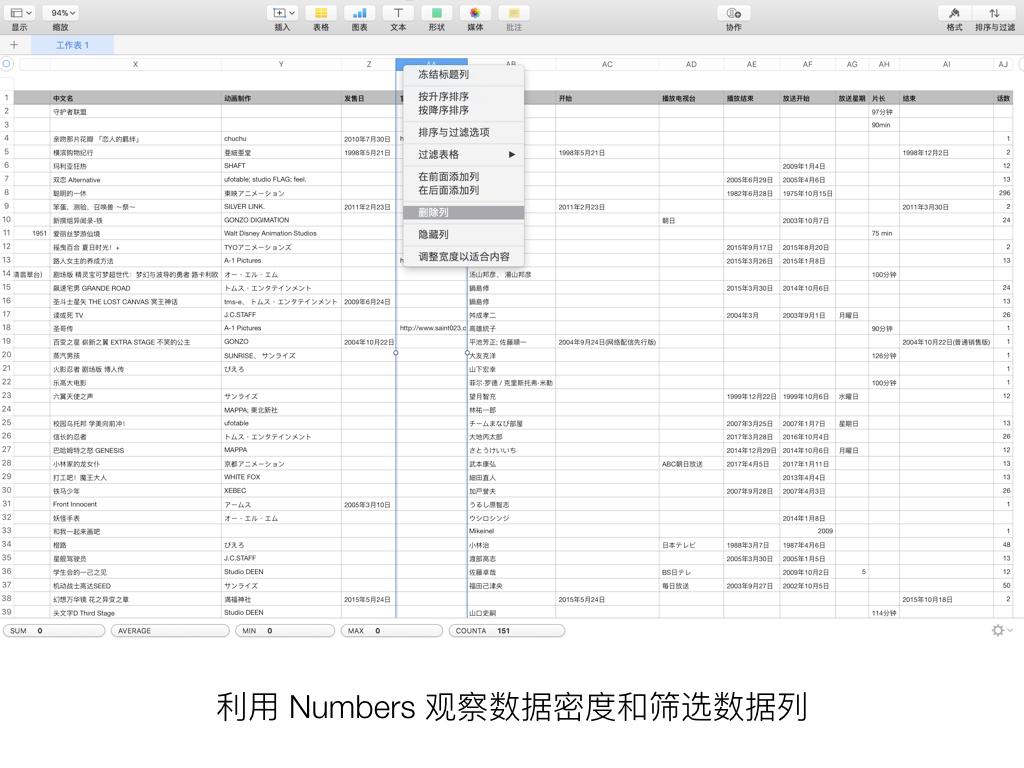
利用 Numbers 观察数据密度和筛选数据列
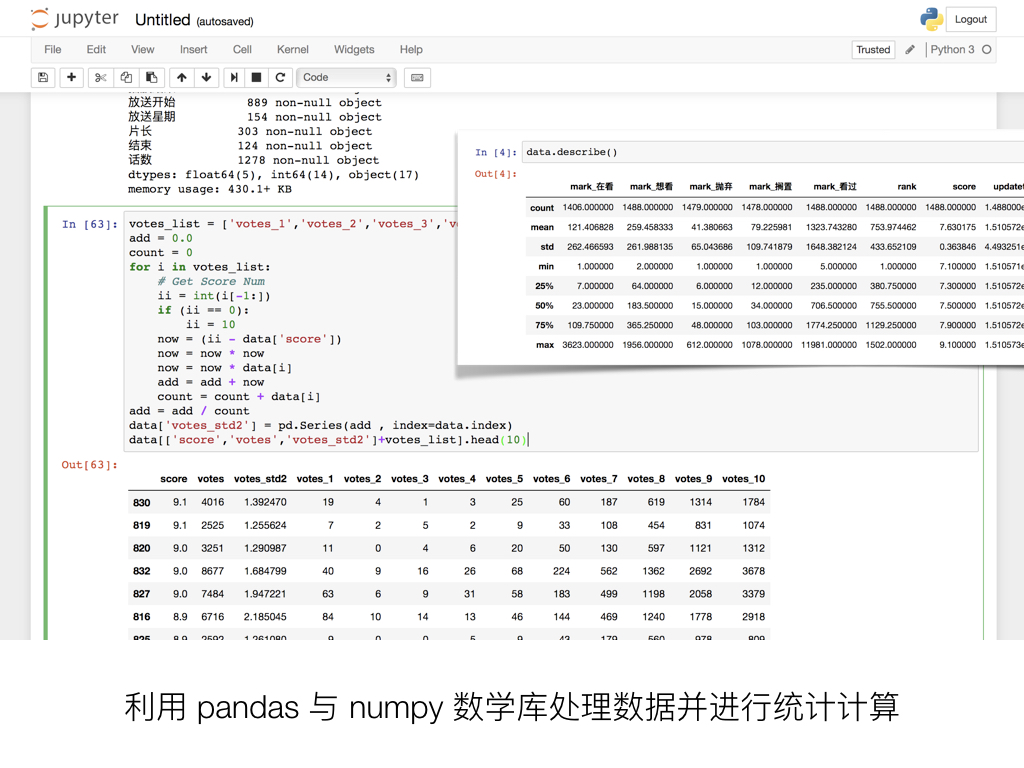
利用 pandas 与 numpy 数学库处理数据并进行统计计算
导出了 CSV 之后,就可以清理数据并进行初步观察了。同样,使用 Excel 打开 CSV 文件可能会遇到编码问题,意外的是 Numbers 并不会。在 Numbers 里你可以肉眼直接观察明显有误的数据、数据量极少即大部分条目没有的数据项,并做简单的处理和增删操作。而在 Anaconda 中启动 jupyter notebook 并调用 pandas 和 numpy ,可以进行数据透视和一系列更强大的统计计算,例如计算每一个属性在条目中的有效内容覆盖率,计算数值数据的均值、方差、中位数、极差等数学统计信息。配合 matplotlib 绘图库,你甚至马上可以画出简单的统计图表。
因为 Bangumi 动画条目中的数据项可以自由添加,因此奇奇怪怪的条目非常的多,而且同样的栏目可能命名不同。因此,在这一步主要做的是删掉有效数据覆盖率低的数据栏目,以及合并同样含义的栏目数据。
未经处理的数据栏目类似这样:
... 上映年度,上映年度:,上映年度(日本),上色,上色担当,上色指导,上色检查,世界観監修,中国大陆上映年度,中文名,中文名:,主动画师,主标题,主演,主演:,主画师,主要动画师,主要机械设定,主要设计,主要设计工作,主要配音,主要配音演员,主题歌作曲,主题歌作曲:,主题歌作词,主题歌作词:,主题歌演出,主题歌演出:,主题歌编曲,主题歌编曲:,乐器设定,产品经理,产地,人形兵器设计,人物作画监督,人物原案,人物原案:,人物监修,人物设定,人物设定&总作画监督,人物设定:,人物设定·作画监督,人物设定辅佐,人物设计,人物造型,仕上助手,企划,企划·制作,企画,企画:,企画プロデューサー 企画営業プロデューサー:,企画プロデュース,企画・制作,企画制作人,企画制作(第1 - 28話)→制作著作(第29 - 39話),企画协力,企画担当,企画立案,作曲,作画,作画Animation,作画协力,作画协力:,作画协调,作画监修,作画监督,作画监督:,作画监督协力,作画监督补佐,作画监督补助,作画监督補佐,作画监督辅,作画监督辅佐,作画監督,作画監督補佐,作畫,作畫監督,作畫監督:,作監補,使徒(运营),先行放送,光盘发售日,全收录,全种族召唤师(制片人),全长,共同制作,其他,其他:,其他电视台,其他电视台:,军事·SF考证,军装装备设计,冲印,出品,出品人,出品公司,出品公司:,出品时间,分级,分镜,分镜:,分镜协力,分镜构图,分镜构图:,分镜构图作监:,分镜誊写,创始神,创意制作人,创意总监,创意顾问,别名,别名:,制作,制作:,制作·发行:,制作·版权,制作·音响制作,制作デスク,制作プロデューサー,制作・著作,制作主任 ...

技术要点
可视化分析
可视化分析
制作好了 CSV 格式的数据集,就可以利用各种可视化工具进行可视化分析了。
这方面,比较出名的在线工具有 visual.ly ,plot.ly ,tableau.com 和 infogr.am ,收费和部分免费的限制各异,对中文的支持程度也不一。开源免费工具中最好用的是 RAW Graph 。如果自己动手从代码开始,最流行的 D3.js , Google Charts 以及百度的 ECharts 都十分不错。你甚至可以直接在本地利用 Python 绘图库,或者尝试 Processing 等可视化编程语言:
当然无论是Processing还是d3.js,chart.js…或是AI,都只是工具而已,能用到什么程度,还是看使用它的人。数据可视化并不是Processing的核心,Processing可以被叫做创意编程语言,那种感觉就好像它已经从设计师跳脱到艺术家了……很多艺术家都使用processing创造自己的作品。甩个接地气的例子,日本女子组合Perfume有个国际推广的项目perfume global website,她们几场看起来各种酷炫的黑科技演唱会都有Processing的一份功劳哦。
额外一提,因为这个契机接触到的 Processing 这门艺术创意性语言十分有意思。一方面这门类 C 语言实际上是目前很火的 Arduino 硬件平台的官方语言,在计算机导论课程上我们接触过的 Arduino IDE 实际上就是 Processing IDE ,这个组合被大量应用于交互艺术方面。另一方面,大力安利这门语言作者的书《The Nature of Code》,中译《代码本色 – 用编程模拟自然系统》,其中涉及到计算机视觉和自然模拟的内容,包括生成噪点和花纹贴图的各种噪声算法、数学分形、模拟力学、物理系统、随机游走、细胞自动机、神经网络的话题,都十分的有趣。

数据可视化工具表
结果展示
后面简单展示一下利用前面抓取的 Bangumi 数据绘制出的分析图片,主要工具是 Plot.ly (免费对数据量有限制) 和 RAW Graph 。其实前述的工具我基本都尝试过一遍,但是最终生成的结果相对好看的只有这两个工具的一小部分。

说明
因为 Plot.ly 的免费使用对数据量有大小限制,所以使用该工具绘制的图标数据量都只有全部条目的 1/3 量。接下来将会以 Score 、 Rank 、 Votes 简称动画的最终评分、排名、打分总人数。
用户观看和评分特征分析

用户观看和评分特征分析
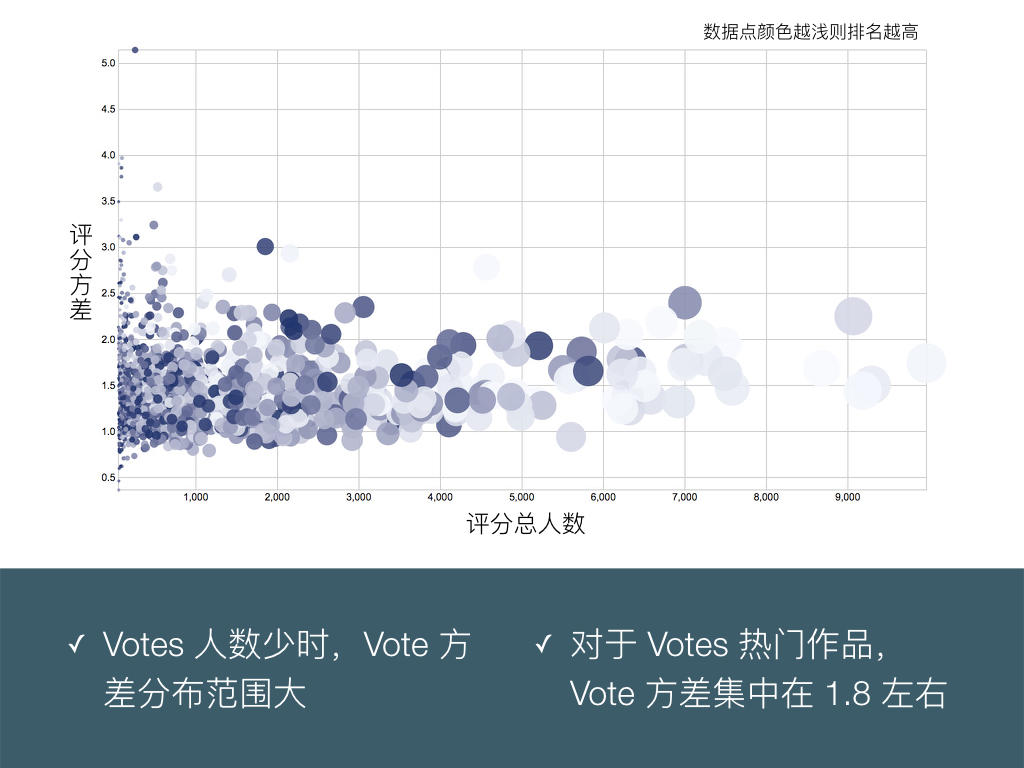
BigDataGumi.016
评分人数和评分方差并不成线性关系:评分人数少的作品,也可能方差小(意见一致),也可能方差大(争议大)。可以看出 Bangumi 用户评分的方差平均值在 1.8 左右,即标准差在 1.3 左右,换句话说,大部分动画的主要评分能够集中在最终评分±1分的分段。
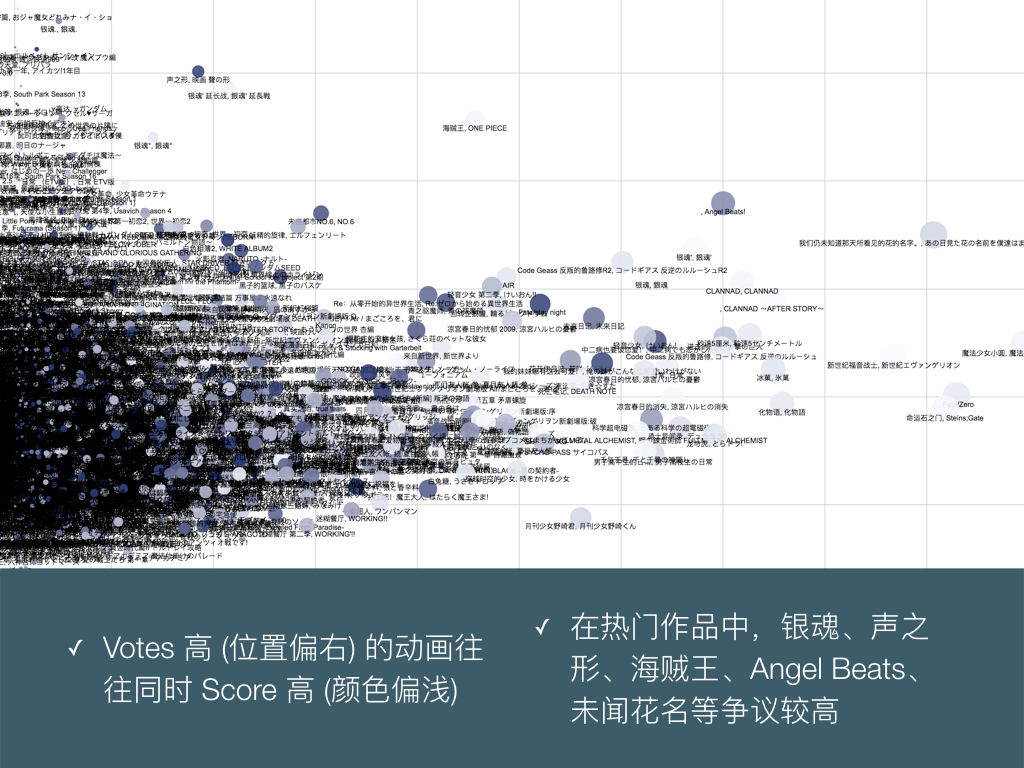
BigDataGumi.017
这是把上一页的图表,加上动画的名称标签展开的结果。我们把最终评分 Score 这个维度通过颜色表现出来,可以发现 Votes 极高,也就是用户评分次数特别多的大热作品,一般也是评分相对高的作品。
这里可能反映了 Bangumi 番组计划这个网站用户群体的性质:这里的热门作品和高分作品十分一致,但是这些所谓的 Bangumi 站内热门作品和 Bilibili 等用户面更广的网站中的大众热门作品,例如Fate、刀剑、小埋、民工番们、轻改名著们等并不重合。
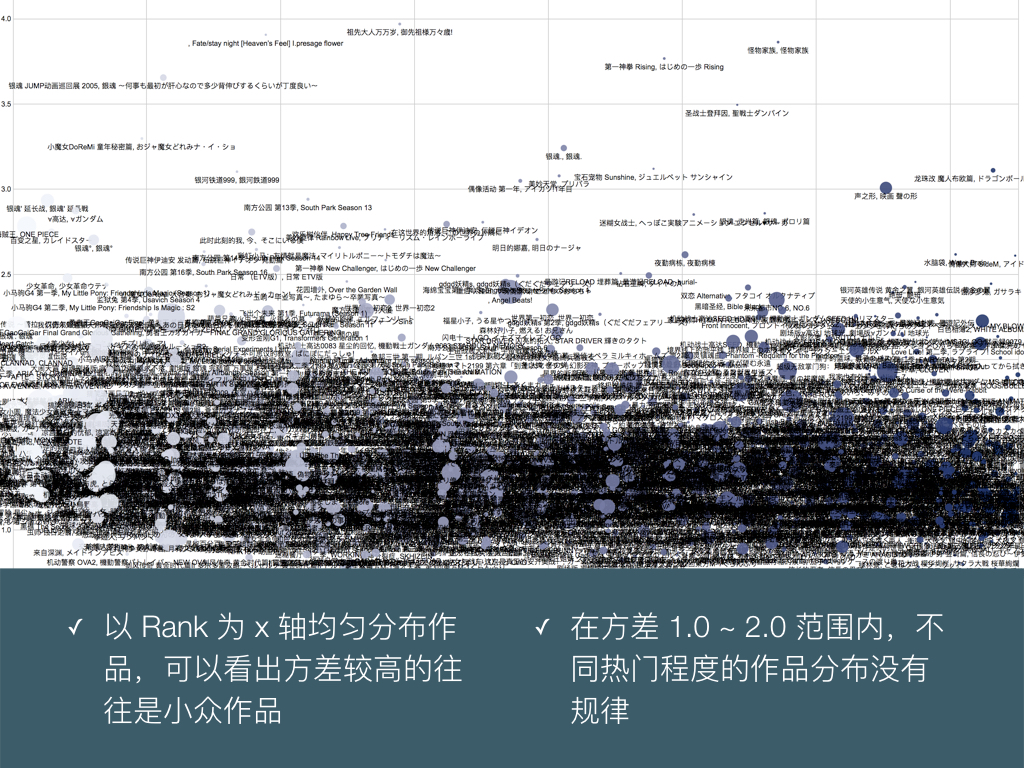
BigDataGumi.018
把作品按 Rank 由高到低从左向右排列,纵轴是方差,可以更清楚的观察到方差拔群的作品:不过大多是评分人数少的小众作品。圆点的大小代表投票人数,其实在这张图我们可以更加感受到:在热门作品中只有声之形、Angel Beats、海贼王、银魂这四部的方差高的不可思议。
无论作品 Rank 多少,是神作还是渣作,方差的分布模式都差不多。并不存在神作或者渣作哪一方往往争议更大的情况。
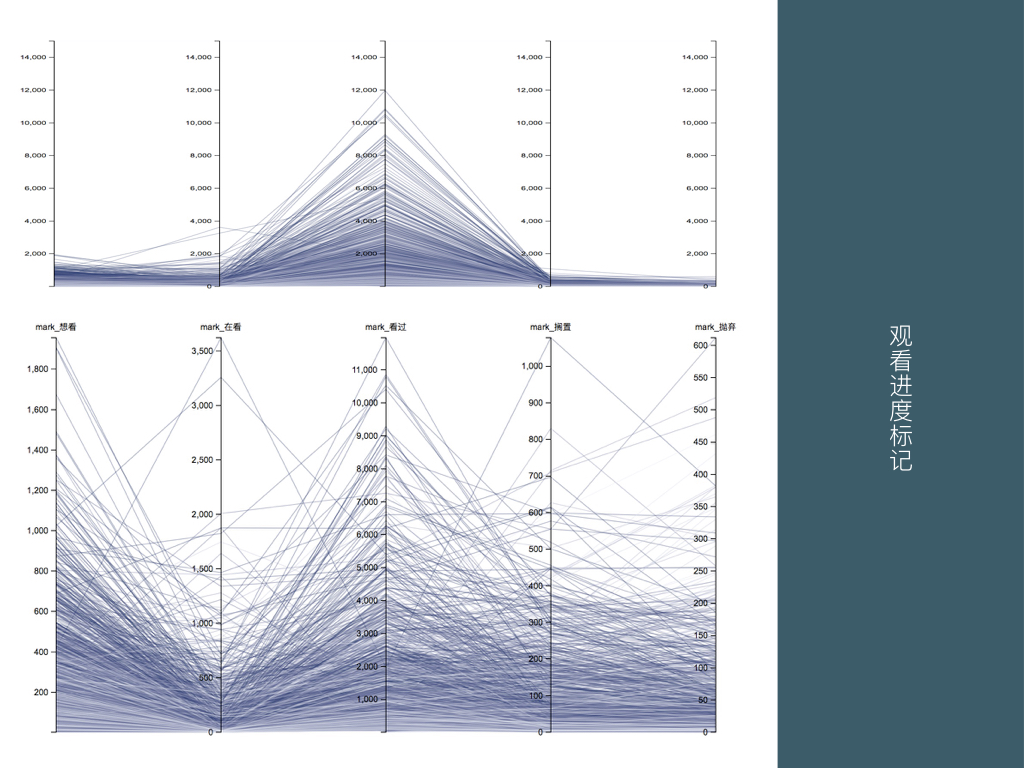
BigDataGumi.019
这里是对 Bangumi 用户标记观看进度的行为分析,第一张图是统一尺寸的坐标轴,显然用户最喜欢标记的是看过,之后是想看和在看,搁置和抛弃的标记相对较少。在看数较多的几个数据,明显是当前正在上映的新番。
下方按比例查看,除了想看和在看受到目前新番播放进度的影响较大,我们可以看出看过、搁置、抛弃这三个属性呈现了有意思的的折线:即存在很少人能看完,大部分人都搁置的作品,甚至很少人搁置,大部分人直接抛弃的作品。
接下来我们可以直接比较搁置和抛弃这两个数据。
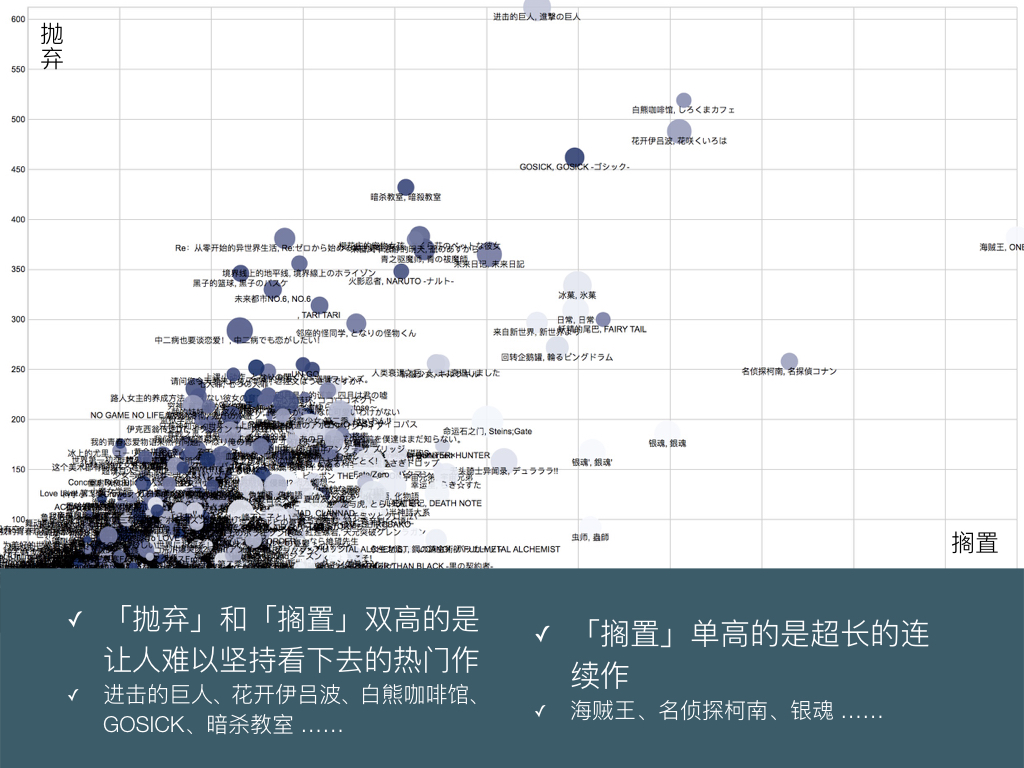
BigDataGumi.020
按搁置数排列靠前的作品:海贼王、名侦探柯南、白熊咖啡馆、花开伊吕波、银魂、妖精的尾巴、银魂’、虫师、冰菓、日常、GOSICK、回转企鹅罐、进击的巨人、来自新世界、无头骑士异闻录、未来日记、命运石之门、幸运星。
按抛弃数排列靠前的作品:进击的巨人、白熊咖啡馆、花开伊吕波、GOSICK、暗杀教室、樱花庄的宠物女孩、海贼王、Re:从零开始的异世界生活、来自风平浪静的明天、青之驱魔师、未来日记、境界线上的地平线、火影忍者、黑子的篮球、冰菓。
这些作品以京都和 PA 的日常番、一粉顶十黑的小学生番、超长民工番和电波名作为主。这里仍然颜色浅的是 Rank 高的作品,从搁置到抛弃两个角落,呈现到由浅到深的线性渐变。看来,评分低的作品可以随手抛弃,而对于评分高的公认神作,大部分用户都选择扔到搁置里,觉得自己总有一天会看完吧。
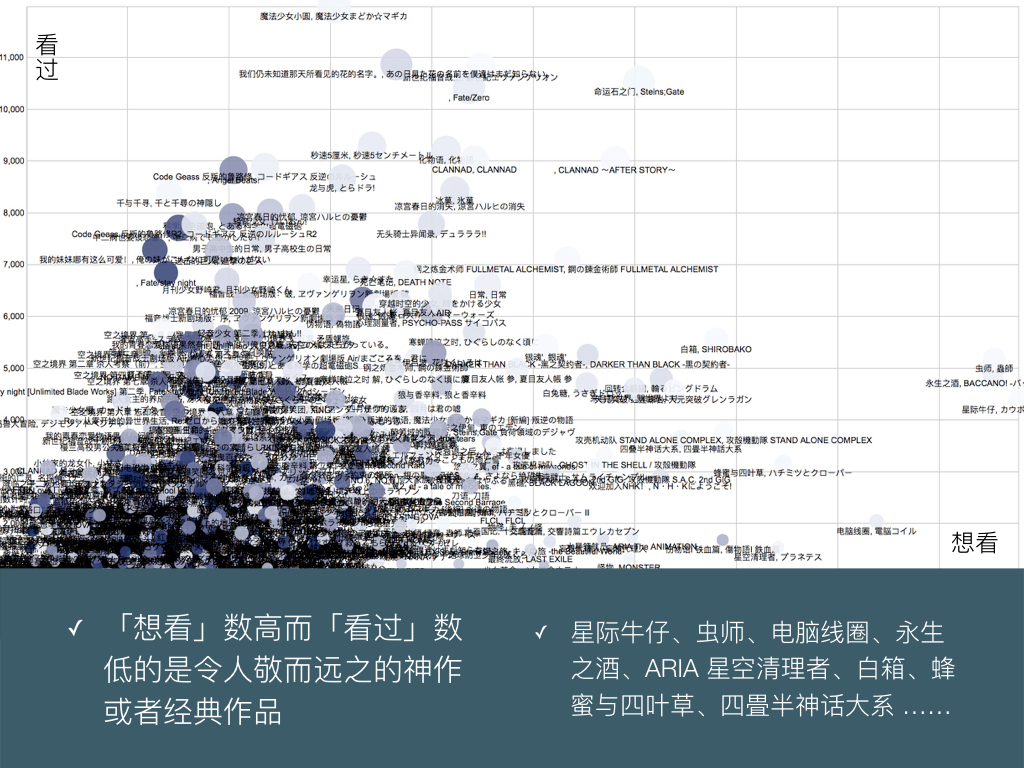
BigDataGumi.021
这里对比想看和看过两个数据,可以发现想看和搁置有异曲同工之妙,区别可能是看过后搁置的作品,热度显著高于和想看而还没看的作品。原来作品的热门程度对是否有过观看行为影响较大 —— 可能这关系到作品的资源多不多,是否成为话题。
筛出图表右侧这些想看数独树一帜,但是其实大部分人最后都没看的作品,就可谓是个简单易懂的补番装逼目录了。
动画制作公司分析

制作公司分析
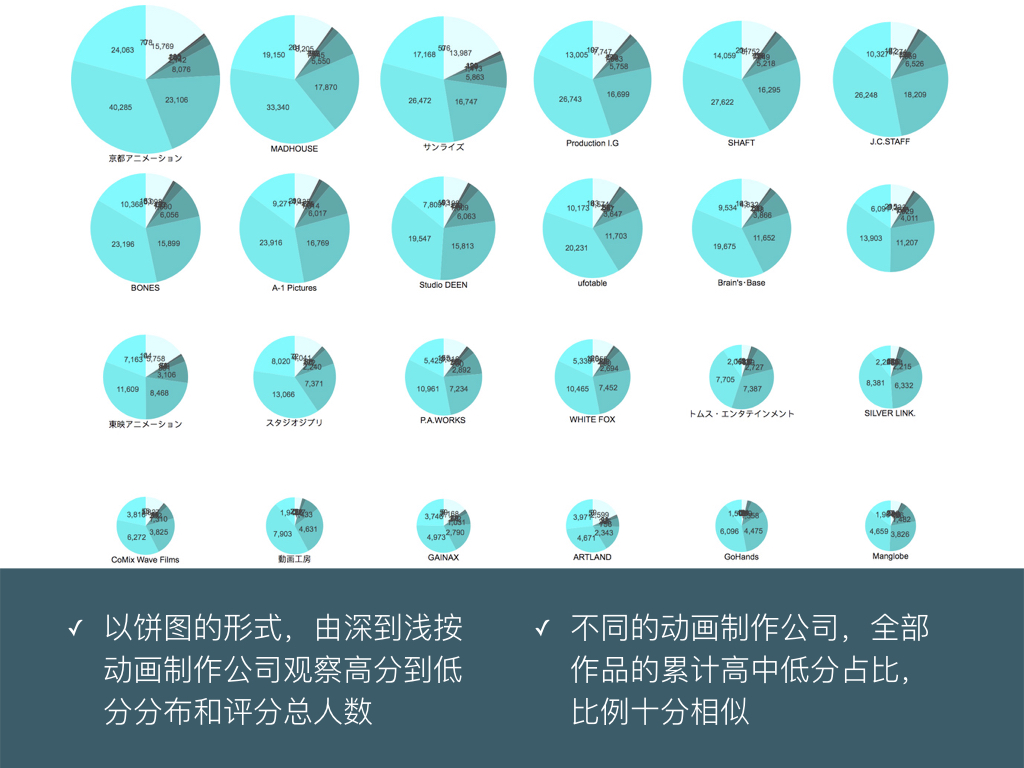
BigDataGumi.023
在我们的印象中,往往对各种动画制作公司有质量高低的成见,比如京都出品必属精品,比如惨遭 A1 动画化,比如骨头社或者宅社的会玩任性 …… 但是实际按动画制作公司所有作品收到的 1~10 的评分绘制成饼图,却发现大部分公司收到的评分比例十分类似。
这是因为我们公认的制作精品数高的公司,往往以少数评分特别高的作品给人留下印象吗?不过,因为这张图数据只含前 1/3 的动画条目,可能对少数烂片特别多的公司有所偏颇 ……
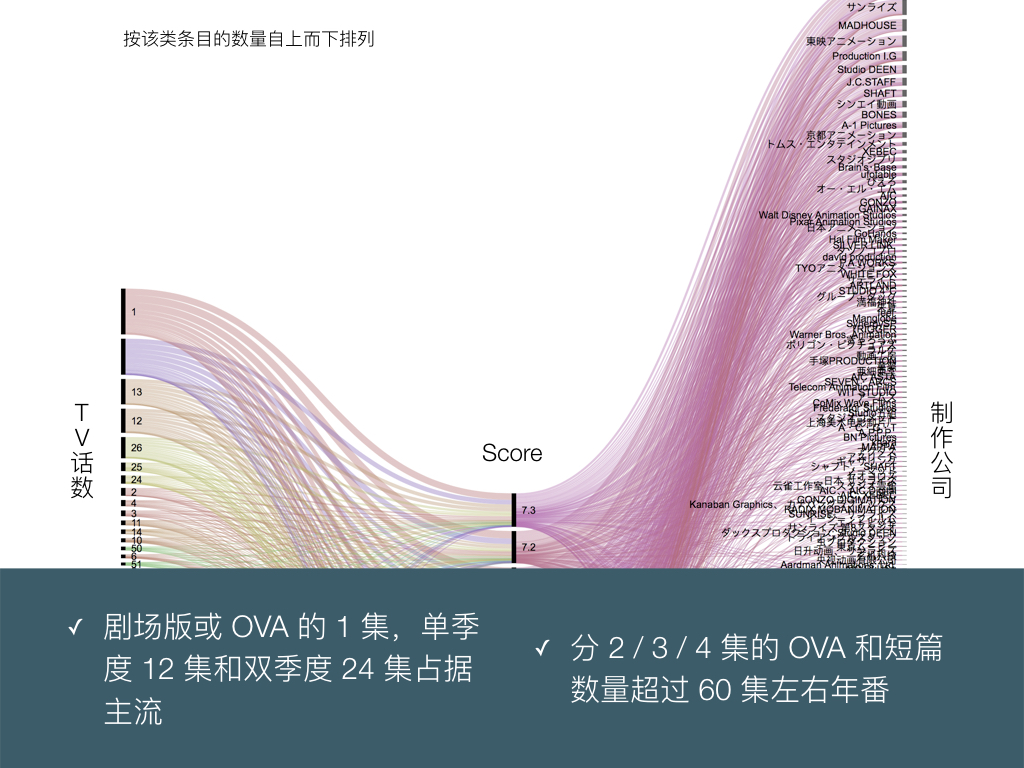
BigDataGumi.024
观察动画条目中集数的分布,以 1 集剧场版或 OVA ,或者单季度 12 双季度 24 长度为主,这是理所当然的结论。动画的集数长度和最终评分似乎并没有什么关联。

BigDataGumi.025
左侧的动画集数、右侧的动画制作公司都按照作品数目由多到少排列。分数段越高,所含的作品就越少。
然而观察高分段作品右侧和制作公司关联的曲线走向,基本都直奔着最顶上走:这意味着最高分段的几部作品,都来自作品数量十分多的实力深厚的大公司,而不是只有几部作品的小作坊。
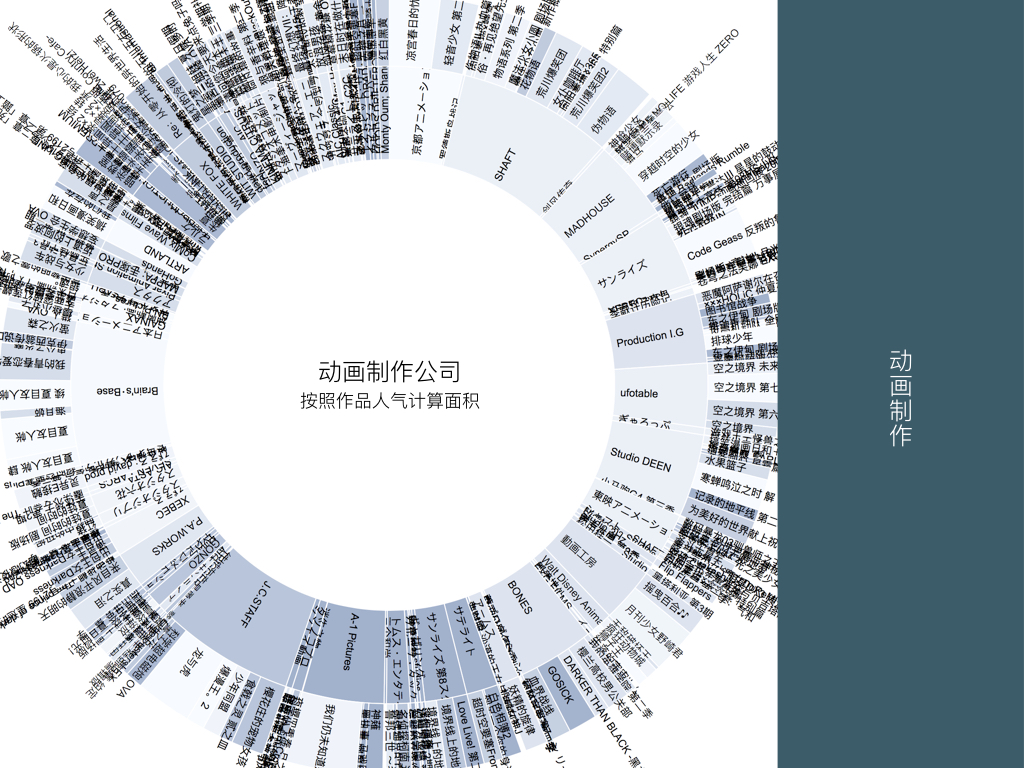
BigDataGumi.026
以辐射图的形式,我们可以观察一些作品的人气或者制作数量特别突出的公司。
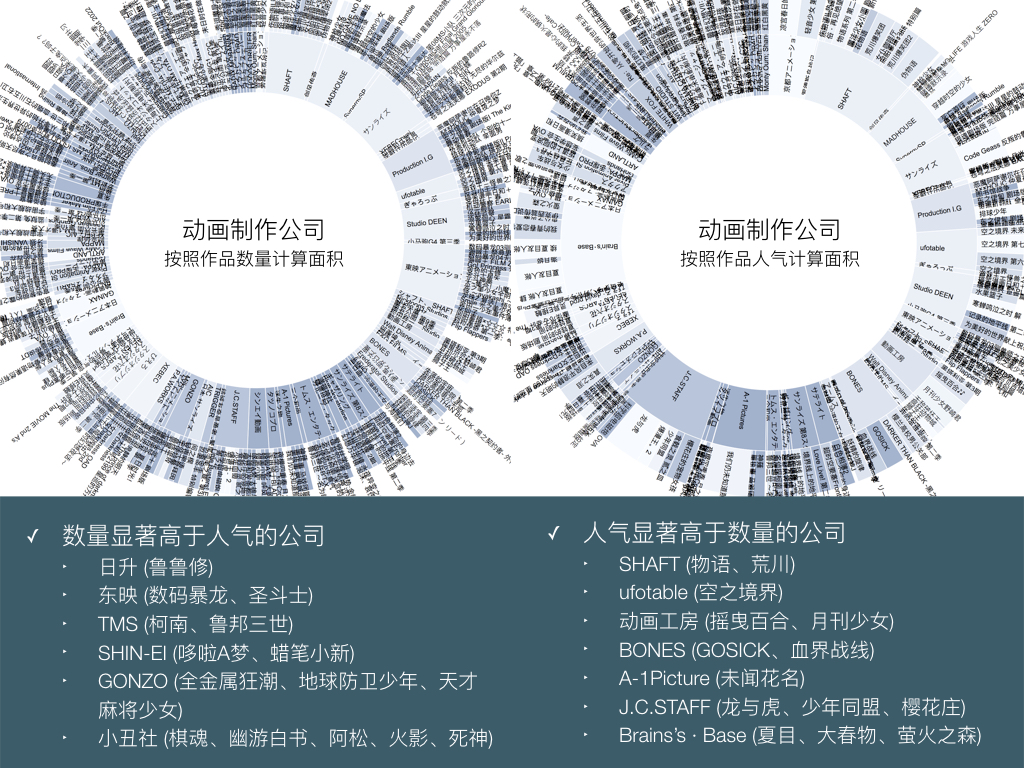
BigDataGumi.027
一部分的动画制作公司数量显著高于人气,另一部分则是人气显著高于数量。其中的作品类型也泾渭分明。
机器学习?
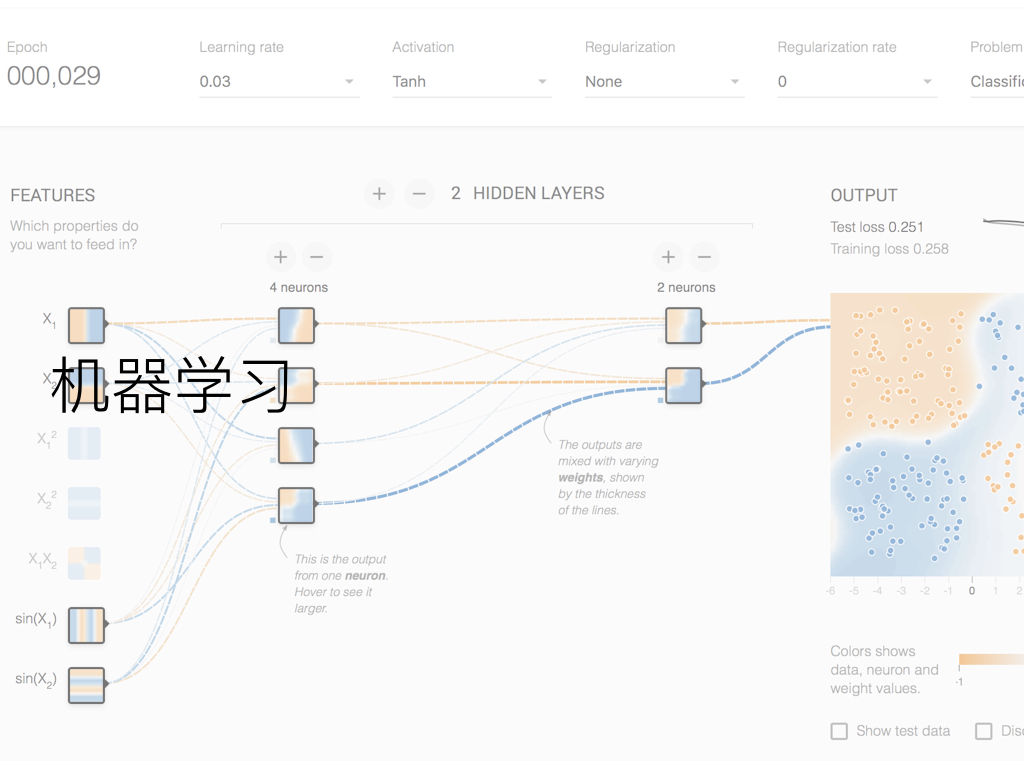
机器学习
之前收集到的大量 STAFF 和标签数据,因为并不是量化的数值,在可视化图表中并没有得到体现。其实在这次的项目开始之初,我就计划利用这份数据做个针对 STAFF 和 TAG 信息,对还未放送或者刚开始放送的新番,进行机器学习训练达到预测最终评分的尝试。

机器学习实践初步想法
由于机器学习和神经网络这些新兴的人工智能领域,我几乎是到了大学后才第一次接触,目前还很陌生,所以截止撰文时只有粗略的想法,并没有取得实际进展。这里就不展开讲述了,等待我入门了相关知识后,再进行 BigDataGumi 项目的二期机器学习阶段吧。
一个有学长在参与的有意思的 Bangumi 相关项目:基于用户评分的针对性动画推荐工具 | Bangumi ,推荐系统研究的成分比较大,使用的似乎是 SVD (奇异值分解) 实现的基于项目的协同过滤推荐 (Item-based Collaborative Filtering Recommendation) 。
结束
THANKS
这次项目一期虽然做的并不是很深入,不过在尝试数据爬虫抓取和可视化分析的过程中,浅尝辄止的接触到了这两个领域很多有意思的技术和工具,也增加了一些 Web 开发和 Python 的经验。应该说,算是接触和了解了数据挖掘这个大学以前闻所未闻的新兴热门领域(毕竟我是个高中信息闭塞了三年,从 2014 年穿越过来的前端开发者 233),也算达到了这门导论课的目的。相比别的同学选的各种尴尬的水课,我觉得这学期选了这门选修课还真是最明智的决定。
数据挖掘可以作为未来一个备选的发展方向,也因为这次的机会认识了学校数字媒体学院的一些在做数据可视化、视觉传达、交互艺术项目的学姐和导师,不得不说,计算机视觉方面我也有几分兴趣。不过目前来说,最想做的还是尝试入门机器学习和神经网络相关的知识。和计算机学院、信息通信学院的几位同学,和在做机器学习和自然语言处理相关项目的研究生学长都提过这个想法,接下来希望能向他们请教学习,把 BigDataGumi 项目二期机器学习标签预测的想法实现了。
项目的进度将会实时更新在知识库的项目草稿: http://note.dimpurr.com/#BigDataGumi%20草稿
以上。
“也因为这次的机会认识了学校数字媒体学院的一些在做数据可视化、视觉传达、交互艺术项目的学姐和导师”只借机会认识学姐不认识学长吗[笑哭]
重点错系列 (
认识的数媒院学长学姐们其实挺多的(毕竟数媒是我初中时的志愿方向 …),不过明确知道在做视觉传达和可视化类的的确只有学姐。后面做机器学习认识的就大部分是学长啦 (
厉害厉害~
要是规模很小的数据或者简单爬一下就好的,我还是直接美丽汤上去就好了。23333
吼啊~
不知道爬bangumi.tv的数据版权怎么说。如果你能更进一步出一本数据分析的同人志薄本,我会考虑购买XD
好厉害!
该怎么入门呢