这学期在学校选修了一门名为「大数据分析技术导论」的公选课,课上纲领性的介绍了目前正处风口的大数据时代的特点,数据挖掘技术的操作过程和实际应用,并从统计分析基础和数据分析工具介绍两方面介绍了一些实践性质的内容。因为是导论性质的课程,课堂内容侧重介绍和应用的性质居多,而对围绕 Hadoop 和 Spark 的实际大数据技术栈,只简单按分类介绍了 MapReduce 、 NoSQL 类数据库、数据集成等常用工具的功能和使用场景,除了最后一节课以 Weka 为例示范了简单的数据集统计分析和经典机器学习模型训练,其他并没有深入讲解到实践操作部分。
作为课程考核的一部分,在分析论文、利用数据集进行分析实验两个选题中,我选择了后者。因为不可能有合适的平台练习分布式存储、批处理和持续集成,最后决定自己爬取一份数据,把简单数据可视化分析的流程跑通。中间踩坑的过程非常多,实际上大部分的想法都没有成功,但是尝试的过程中,对大数据领域工作流和技术栈的加深了解,应该算是达到了这个导论课本身的意义。
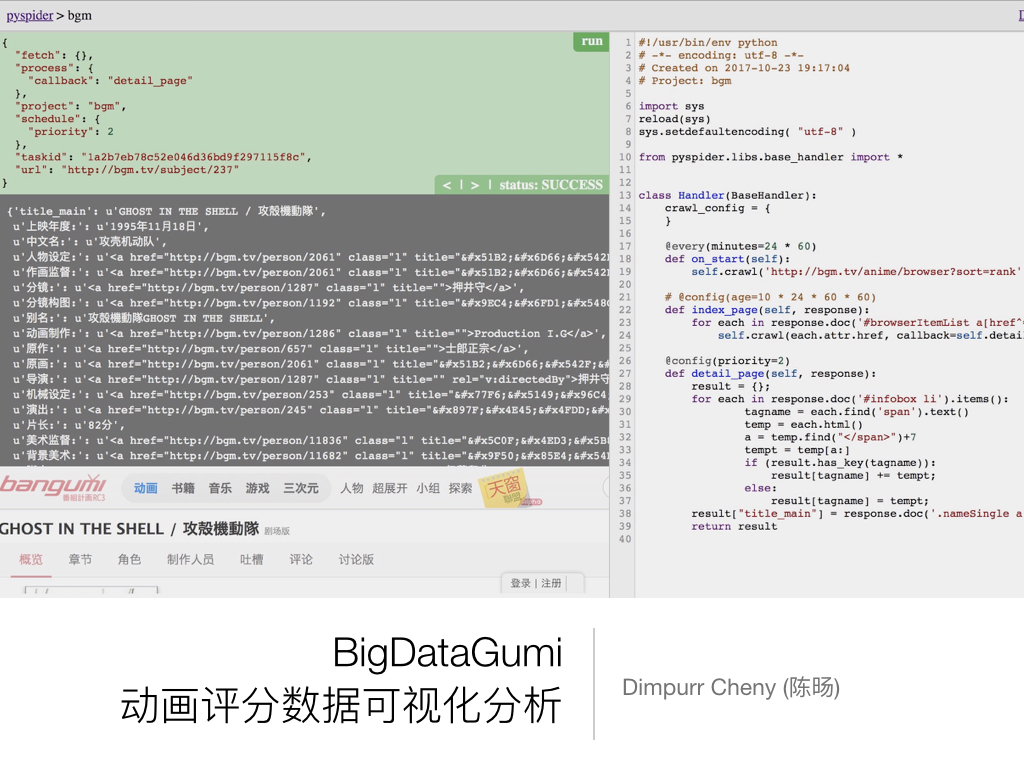
BigDataGumi 动画评分数据可视化分析
这篇文章记录了利用 Bangumi 番组计划 (bgm.tv) 网站的动画条目和评分数据,进行数据统计分析的项目「BigDataGumi」的初步进展,包括设计网页爬虫抓取数据、利用可视化分析工具尝试获取有价值信息的实际操作部分。一些没有实现的想法和没有呈现在结果中的可能的学习方向,也会作为学习经历的一部分记录。项目的下一步想法是训练一个 tag-orinted 的机器学习模型,能够计算动画的 STAFF 构成和 TAG 标签属性对评分影响的权重,并根据 STAFF 和 TAG 数据预测新番的最终稳定评分,在撰写本文时仍在进行中。
尽管这个项目目前的进展不怎么大数据,不过如果你和之前的我一样从未接触过数据挖掘这个领域,从这篇文章你可以看到简单的数据爬取和可视化分析的操作流程,并且了解到数据分析部分领域的概貌。涉及到的都是非常粗浅的内容,见笑。 READ MORE →